今天通过两个具体的实例,教大家从零开始使用 PHP 来抓取需要的数据。
准备工作
首先,你需要准备一个 Html 编辑器(如 notepad++),以及一个支持 PHP 的网站空间。
新建一个 PHP 文件,命名为 get.php
第一行代码
打开 get.php ,在里面输入
- <?php
- echo 'hello php';
- ?>
保存,然后将这个 PHP 文件上传至你的网站空间,通过浏览器访问这个 PHP 文件,浏览器输出 “hello php”。恭喜你!已经写下了第一行 PHP 代码!
别看只有小小的三行代码,其实包含了很多知识点!(敲黑板……)
第一行代码的 尖括号+问号+php 是 PHP 语言的开始标记,所有的 PHP 代码都要写在开始标记的后面。
第二行代码是一个输出语句,用 echo 输出一个字符串。字符串用单引号包起来。其实用双引号也是一样的。双引号与单引号的区别是双引号中可以直接放变量。每一句 PHP 代码的结尾都用半角的分号表示结束。
第三行的 问号+反尖括号 是 PHP 的结束标记,用于表示 PHP 代码到这里就全部结束了。如果后面没有了其它的 HTML 代码,那么结束标记可以省略
初试信息抓取
以下内容以抓取 图灵机器人 的 Api 接口内容为例:
图灵机器人 提供了一个虚拟聊天机器人数据接口,它的调用方式如下:
- http://www.tuling123.com/openapi/api?key=e825286159f9f57db1b597995d72ae2b&info=你要说的话
我们可以直接在浏览器中访问这个接口地址。浏览器会显示如下内容:
- {"code":100000,"text":"我有话要对谁说呢"}
这种用大括号括起来的数据格式叫 JSON。待会我们再谈如何去解析 JSON 数据。
现在我们要做的是通过 PHP 来抓取上述接口的内容。
PHP 有一个很方便的文件读取函数:file_get_contents()。我们可以直接用 file_get_contents('要抓取的网址') 来获取指定网址(接口)的内容
代码示例:
- <?php
- $data = file_get_contents('http://www.tuling123.com/openapi/api?key=e825286159f9f57db1b597995d72ae2b&info=你好');
- echo $data;
- ?>
运行这行代码,浏览器中显示的应该是和直接去访问原接口地址类似的内容。这就说明我们已经成功地从图灵的接口抓取到了数据。
JSON 数据的解析
下面,我们需要从原始的 JSON 中解析出 "text" 这个键值的内容,也就是机器人回复你的内容。
同样的,PHP 也提供了一个非常方便的用于解析 JSON 的函数:json_decode()。这个函数有两个参数,第一个参数是原始 JSON 数据,第二个参数 assoc 用于指定返回数据的格式,如果为 true 返回数组格式,如果为 false 则返回一个对象。
我们这里将 JSON 解析成数组来使用。
代码如下:
- <?php
- $data = file_get_contents('http://www.tuling123.com/openapi/api?key=e825286159f9f57db1b597995d72ae2b&info=你好'); // 从图灵的接口获取数据
- $arr = json_decode($data, true); // 将获取到的 JSON 数据解析成数组
- echo $arr['text']; // 输出数组中的 “text” 值(也就是之前 JSON 中的“text”键值中的内容)
- ?>
现在我们去运行代码,浏览器中只会显示机器人回复的内容了,没有了其它的 json 内容。
参数获取
上面的代码中,接口中发送的字符串(也就是我们发给机器人)的文字是固定的,如果要给机器人发不同的内容,那么只能修改代码……这样很不方便。
其实,我们可以通过 get 的方式传递给 PHP 一些参数,以此来动态改变内容。
PHP 中可以使用 $_GET() 来获取 get 方式发送的数据。
那么问题来了,什么是 get 发送数据呢?仔细研究一下图灵的接口,它的数据传递方式是 图灵接口+你要说的话 这种数据传送方式就是 get。你如果直接在浏览器里访问可以在地址栏看到全部的 get 发送的数据。
加了 get 数据传递后的代码如下:
- <?php
- $get = $_GET['says']; // 获取 get 数据
- $data = file_get_contents('http://www.tuling123.com/openapi/api?key=e825286159f9f57db1b597995d72ae2b&info='.$get); // 从图灵的接口获取数据
- $arr = json_decode($data, true); // 将获取到的数据解析成 JSON 格式
- echo $arr['text']; // 输出数组中的 “text” 值(也就是之前 JSON 中的“text”键值中的内容)
- ?>
现在,你可以直接跟你的机器人“对话”了。
方法就是访问
- http://你的网址/get.php?says=你想说的话
至此,你已经学会了抓取 Api 接口的内容并解析 JSON 数据。
但是有时我们抓取到的数据格式并不是 JSON,那该怎么办呢?且听我慢慢说来……
初识 Curl
上面介绍了一个抓取网页数据的 PHP 函数:file_get_contents() ,这个函数使用起来非常简单,但却不是万能的。
下面以 126 的 IP 定位接口为例:
- http://ip.ws.126.net/ipquery
直接访问这个接口地址,你会发现浏览器返回了你当前的 省份 和 城市 信息。
我们再尝试用 file_get_contents() 来抓取这个接口的内容。
- <?php
- $data = file_get_contents('http://ip.ws.126.net/ipquery'); // 从接口获取数据
- echo $data;
- ?>
运行这行代码,你会发现浏览器中输出的并不是你本地的地址,而是服务器的地址。
你用 PHP 从服务器去抓取,接口那边获取到的是你服务器的 IP,然后返回服务器的地址,没毛病!
那么,可不可以在服务器那边伪造一个 IP 地址,然后去抓取呢?
当然可以~这时就得是 Curl 上场了。Curl 的参数有很多,用法也很复杂。具体的可以百度去了解。我这里直接提供一个封装好的函数,可以拿来直接使用。
- /**
- * Curl 伪造 IP 并从指定网址获取数据
- * @param $url 接口地址
- * @param $ip 伪造的 IP
- * @return 抓取到的内容
- */
- function myCurl($url, $ip){
- $ch = curl_init(); // Curl 初始化
- $timeout = 30; // 超时时间:30s
- $ua='Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'; // 伪造抓取 UA
- curl_setopt($ch, CURLOPT_URL, $url); // 设置 Curl 目标
- curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // Curl 请求有返回的值
- curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $timeout); // 设置抓取超时时间
- curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); // 跟踪重定向
- curl_setopt($ch, CURLOPT_ENCODING, ""); // 设置编码
- curl_setopt($ch, CURLOPT_REFERER, $url); // 伪造来源网址
- curl_setopt($ch, CURLOPT_HTTPHEADER, array('X-FORWARDED-FOR:'.$ip, 'CLIENT-IP:'.$ip)); //伪造IP
- curl_setopt($ch, CURLOPT_USERAGENT, $ua); // 伪造ua
- curl_setopt($ch, CURLOPT_ENCODING, 'gzip'); // 取消gzip压缩
- curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, FALSE); // https请求 不验证证书和hosts
- curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, FALSE);
- $content = curl_exec($ch);
- curl_close($ch); // 结束 Curl
- return $content; // 函数返回内容
- }
有了这个函数你就可以直接通过 myCurl('目标网址', '伪造的IP') 来伪造 IP 并获取数据了。
示例如下:
- <?php
- $data = myCurl('http://ip.ws.126.net/ipquery', '223.81.141.38'); // 伪造 IP 并获取数据
- echo $data;
- /**
- * Curl 伪造 IP 并从指定网址获取数据
- * @param $url 接口地址
- * @param $ip 伪造的 IP
- * @return 抓取到的内容
- */
- function myCurl($url, $ip){
- $ch = curl_init(); // Curl 初始化
- $timeout = 30; // 超时时间:30s
- $ua='Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'; // 伪造抓取 UA
- curl_setopt($ch, CURLOPT_URL, $url); // 设置 Curl 目标
- curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // Curl 请求有返回的值
- curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $timeout); // 设置抓取超时时间
- curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); // 跟踪重定向
- curl_setopt($ch, CURLOPT_ENCODING, ""); // 设置编码
- curl_setopt($ch, CURLOPT_REFERER, $url); // 伪造来源网址
- curl_setopt($ch, CURLOPT_HTTPHEADER, array('X-FORWARDED-FOR:'.$ip, 'CLIENT-IP:'.$ip)); //伪造IP
- curl_setopt($ch, CURLOPT_USERAGENT, $ua); // 伪造ua
- curl_setopt($ch, CURLOPT_ENCODING, 'gzip'); // 取消gzip压缩
- curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, FALSE); // https请求 不验证证书和hosts
- curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, FALSE);
- $content = curl_exec($ch);
- curl_close($ch); // 结束 Curl
- return $content; // 函数返回内容
- }
- ?>
通过修改 IP 值,你就可以获取任意 IP 对应的地址了 [坏笑] 一个 IP 查询工具就这样诞生了!
然鹅,,你肯定也注意到了。以上获取到的数据内容似乎有点乱:
![]()
如果我只想获取到其中的省份和城市信息,该怎么办呢?
细心的你肯定发现了,这个数据并不是 JSON 格式的,因此也就不能通过上文的 解析 JSON 的方法来进行解析。那该怎么办呢?
正则表达式入门
每到要从一堆杂乱的内容中获取内容,就是正则表达式登场的时候了!
仔细观察返回的数据,其实内容中除了城市和省份,其它的内容是固定的,格式如下:
var lo="省份", lc="城市";
我们可以以此来编写正则表达式。推荐使用 站长工具的正则表达式测试工具(http://tool.chinaz.com/regex/),可以实时测试匹配结果,很方便。没接触过正则表达式的也可以查阅工具中的正则表达式语法说明来现学。
这是我写好的正则表达式内容。可以完美地匹配出需要的内容
- lo="(.*)", lc="(.*)";
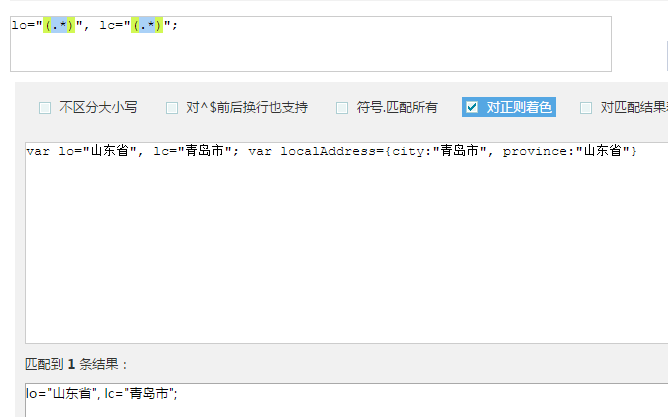
有了正则表达式,再就需要用 PHP 来从原始数据中来匹配出来了。于是乎我们又用上了一个新的 PHP 函数:preg_match()
它的用法是这样的:
- preg_match('正则表达式', '输入内容', '存储匹配结果的变量’)
又到了上代码的时间:
- <?php
- $data = myCurl('http://ip.ws.126.net/ipquery', '223.81.141.38'); // 伪造 IP 并获取数据
- preg_match('/lo="(.*)", lc="(.*)";/', $data, $arr); // 正则提取
- /**
- 注:
- 正则表达式中括号括起来的部分代表要匹配的内容,
- 像上面这个正则表达式中有两个括号括起来的部分,自然就代表会匹配出两个内容。
- 正则匹配的结果会以【数组】的形式赋值给第三个参数,也就是 $arr
- 那么……
- $arr[0]是整个正则表达式匹配出的内容(无视括号)
- $arr[1]是第一个括号中匹配出的内容
- $arr[2]是第二个括号中匹配出的内容
- .
- .
- $arr[n]是第N个括号中匹配出的内容(如果有的话。。)
- **/
- echo $arr[1].' - '.$arr[2]; // 输出
- /**
- * Curl 伪造 IP 并从指定网址获取数据
- * @param $url 接口地址
- * @param $ip 伪造的 IP
- * @return 抓取到的内容
- */
- function myCurl($url, $ip){
- $ch = curl_init(); // Curl 初始化
- $timeout = 30; // 超时时间:30s
- $ua='Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'; // 伪造抓取 UA
- curl_setopt($ch, CURLOPT_URL, $url); // 设置 Curl 目标
- curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // Curl 请求有返回的值
- curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $timeout); // 设置抓取超时时间
- curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); // 跟踪重定向
- curl_setopt($ch, CURLOPT_ENCODING, ""); // 设置编码
- curl_setopt($ch, CURLOPT_REFERER, $url); // 伪造来源网址
- curl_setopt($ch, CURLOPT_HTTPHEADER, array('X-FORWARDED-FOR:'.$ip, 'CLIENT-IP:'.$ip)); //伪造IP
- curl_setopt($ch, CURLOPT_USERAGENT, $ua); // 伪造ua
- curl_setopt($ch, CURLOPT_ENCODING, 'gzip'); // 取消gzip压缩
- curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, FALSE); // https请求 不验证证书和hosts
- curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, FALSE);
- $content = curl_exec($ch);
- curl_close($ch); // 结束 Curl
- return $content; // 函数返回内容
- }
- ?>
结束语
本文从零开始,大致地讲了下使用 PHP 抓取数据并进行解析、获取自己想要的内容的方法,旨在起到一个抛砖引玉的作用。因为时间及水平有限,可能有些地方说得比较笼统。
如果还要不懂的地方,可以尝试通过百度来解惑,百度上的很多教程都比较详细。
如果有百度了还没解决的问题,可以直接在下面留言。
本文作者为mengkun,转载请注明。

电影网采集API,自动更新,会做吗?回复我一下
@互联影吧暂时没时间接开发项目,抱歉~
只会python的爬虫,想不到PHP也可以
那么问题来了
查看图片
这种情况怎么弄呢
查看图片
还有这种,为什么这种接口可以用html的代码来实现
自学半个月,就需要这样干货,多多更新[aru_89]
网上很少有php采集的教程,希望博主能高产似母猪[aru_3]
如果要爬取好几层呢,
curl_setopt($ch, CURLOPT_URL, $url); // 设置 Curl 目标
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // Curl 请求有返回的值
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $timeout); // 设置抓取超时时间
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); // 跟踪重定向
curl_setopt($ch, CURLOPT_ENCODING, ""); // 设置编码
curl_setopt($ch, CURLOPT_REFERER, $url); // 伪造来源网址
curl_setopt($ch, CURLOPT_HTTPHEADER, array('X-FORWARDED-FOR:'.$ip, 'CLIENT-IP:'.$ip)); //伪造IP
curl_setopt($ch, CURLOPT_USERAGENT, $ua); // 伪造ua
curl_setopt($ch, CURLOPT_ENCODING, 'gzip'); // 取消gzip压缩
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, FALSE); // https请求 不验证证书和hosts
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, FALSE);
这一段要写好几遍吗?
@Song不是封装好了函数吗,直接多调用几次 myCurl($url, $ip) 就行了。
例如:
$baidu = myCurl('https://www.baidu.com', ''); $google = myCurl('https://www.google.com', ''); ……嗯,继续出教程,不要停
表示本菜鸟看不懂
请教一下站长,我使用你这个文章的curl拿到了百度音乐的播放地址,但是在http打开页面的发起请求拿到的地址,添加到audio标签,却不能播放,返回403报错,提示被禁止访问,没有权限。这个能解决吗?[aru_15]
能抓一言的吗?我想自己搭个同步的api
大佬,我把你的评论扒走用行不?[aru_18]
很不错,希望长更新
这教程写的不错,适合新手学习,更是适合懒人直接复制粘贴就能用了。
@蓝叶活捉蓝叶大佬 [wb_doge]
非常好,适合我等菜鸟,茅塞顿开啊
php抓取没什么问题,之前做过微信模拟之类的,但 是记得IP不是这么轻易可以伪造的吧,,好像终极方法是IP代理,这有点不好弄,我没有试试过
@小李PHP 只能伪造 HTTP_CLIENT_IP 和 HTTP_X_FORWARDED_FOR。通过伪造这两项已经能“骗”过大多数的程序了。
如果对方是通过 REMOTE_ADDR 来进行判断,那么只能是用代理了。但使用代理也只能是变成成代理服务器的 IP 地址,并不能达成想随意伪造 IP 的目的。
不错
博主,我问个问题,我的影视网站获取的360列表,但是我添加了尝鲜电影,如图 查看图片
我是直接新建了一个li.php页面添加的电影列表,然后在index里添加了include 'li.php',显示正常,列表代码截图如下:
查看图片
但是我添加电影需要去编辑代码比较麻烦。现在想通过比如新建一个页面,在这个页面有几个表单框,填写播放链接、图片地址等信息之后前段自动显示,这样的是不是很麻烦?如果不麻烦的话请指点一下,如果麻烦的话我就放弃了。。。
@死神影视你的意思就是做一个后台是吧?
其实只是少量的数据修改弄后台没必要,确实有些复杂。
你可以把这些可复用的内容(<li>中间的内容)写成一个函数,然后通过函数来调用输出。比如
function movie($name, $url, $cover) {
.......
}
然后通过
movie('电影名','链接','封面');
这种形式来输出,就简单些。
@mengkun好吧,复杂的话我就不弄了,没学过这个,复杂的我弄不来。。只会修改一点代码,关于程序是一点不懂。。。谢谢了。
博主 用jsonp的方式能不能做到呢?
@游魂有的接口支持 jsonp,有的不支持。本文主题是使用 PHP 抓取解析,所以特意都选的不支持 jsonp 的接口作为示例
@mengkun哦哦 有个问题求助下 我用的emlog的邮件smtp插件 死活不能用 有时间能帮我看看原因么?
@游魂不能。没时间。对 emlog 不了解。不过猜测是服务器发送邮件的端口被封堵引起的,因为最近一大批服务器都封堵了通常用于发送邮件的 25 端口。办法是换一个不用 25 端口的邮件发送方式(具体请百度)
@游魂坤哥说的不错,端口封堵,解决办法,用qq邮箱,改一下代码,smtp为qq,端口465,完美解决。
获取360数据,很多需要正则表达式
mk大佬真流弊。虽然看了也还是不怎么懂,可以慢慢看
牛逼 这姿势可以 我居然能看完这么长的文章。看起来挺简单的
实在太棒了,我经常会来看看有没有新的东西,知识也好,生活趣事也好,都乐意看一看,最近我决心要学织梦仿站,从代码开始学起!
不懂英文,学起来好像很费劲!!!!!!!!!
@fy789编程与英文水平的高低没有必然的联系。
你可以将里面的字母当做拼音来看,是一样的。
因为就算是认识这些单词的外国人学起来还是得一个个去学习它的具体的用法
打卡打卡! [wb_二哈]
打卡..嘀嘀嘀...
看样子这是一个系列的文章 [疑问] 多发些,我也学习学习
@阿珏博客不定期更新
感谢分享
如此长文,叫我如何消化。只有两个字适合我——远离
@广元巴士一步步来尝试,你会发现其实很简单。
等到学会了会有一种"相识恨晚"的感觉 #(滑稽)
因为这项技能的用处实在是太多了 #(笑眼)
不错 特别详细
很棒的教程,内容很丰富,涉及到php语法、json数据解析、php正则、php函数,感谢分享